During a recent project I came accross a common problem when handling content in a frontend. The situation is pretty common, content is stored sowhere on S3 in some structure and users should be able to access it quickly, but only for authorized individuals. Meaning there should be some sort of authentication using some Identity Provider (IDP). In adition the access control should be able to support grouping to bundle access rights for the content.
The articles approach uses cookies to store tokens, which are validated using a lambda@edge. Maybe that’s the better approach to take. For my usecase it’s ok to send an access token in the header, for every request. The only relevant thing was: Requests should be cached by Cloudfront as long as the validation succeeds.
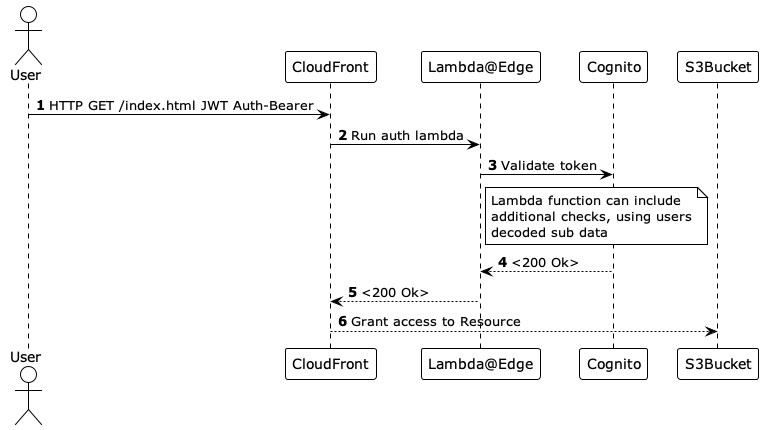
Basic solution
As shown in the overview diagram the solution is constructed, using the following service components:
- Store assets in a secure S3 bucket (default settings, no public access)
- Fast access to assets on the S3 origin using Cloudfront Distributions as CDN
- Authentication via OAuth with lambda@edge
On S3 there’s not alot to talk about, just create a bucket with default settings, which blocks all public access. This is what we want, check. Assets should be accessed via Cloudfront. This enables low latency and high transfer speeds. For Cloudfront pricing take a look at this overview.
S3 & Cloudfront
In order to link S3 to your Cloudfront CDN, just create a distribution that resolves the
S3 bucket as the distribution’s origin. For now there’s no lambda function to secure our
CDN, meaning when you access <dist-url>/path/to/your/ressource-on-bucket.png, you get a
response. Ok, now the S3 bucket is effectivly public. Now we need an easy way to secure
content on the bucket.
Cognito
Now we can’t verify the authorization of user. We have no identity provider, to create identities for us. There are many IDPs e.g.: Github, Google, …. Most providers use OAuth2 as authentication flow. An authentifaction flow is basically the process in which an individual proofs the identity to the provider, which involves some process of verification. In case you want to go all the way on this topic see the spec rfc6750.
So Cognito is our identity provider which creates identities for our users, which we can verify by decoding tokens with encryption information (public keys) we obtain from cognito. Like this we can identify an individual as a member of our user pool or group and thus grant or deny access to resources.
Lambda@edge
Since our distribution exposes the bucket now, we need a security layer on top of this. Here is where lambda@edge comes in. The name tells what it does, executing a lambda function close at the edge of network. There are a few limitations for an edge function:
- Lambda has to be in
us-east-1(US East, N. Virginia) - You can’t configure your Lambda function to access resources inside your VPC
- Edge function and distribution must be owned by the same AWS account
- Function code and dependencies (zip) must be
< 10MB
The first step is always to find a sample of the event the function has to handle. In this case the following can be used:
{
"Records": [
{
"cf": {
"request": {
"headers": {
"host": [{"value": "d123.cf.net","key": "Host"}],
"authorization": [{"value": "Bearer <token>","key": "Authorization"}]
},
"clientIp": "2001:cdba::3257:9652",
"uri": "path/to/resource.jpg",
"method": "GET"
},
"config": {"distributionId": "<dist-id>"}
}
}
]
}
So the first thing we’re interested in is the request header. There’s our authentication
head. For getting started with how such an HTTP header could look like see
Mozillas Web/HTTP/Authentication.
In our example we want to work with cognito as IDP, since we’re on AWS anyways. Since
we’ll obtain some tokens (access, id & refresh token (OAuth2)) from cognito we’ll need the
Bearer authentication scheme. At this point we already passed the authentication flow with
username/password in the frontend and obtained an access token from cognito, which is sent to
cloudfront in the header. The example show that too. You just need to exchange Bearer <token>
with the actual token.
Check the header
So let’s check if the header is structured the way we expect:
def check_headers(headers: Dict) -> Union[str, bool]:
"""Check header content for 'Authorization: Bearer <token>' in request
authorization (key, values).
"""
if "authorization" not in headers.keys():
return False
# Needs only one auth header. Change this when required.
if not len(headers["authorization"]) == 1:
return False
token_string = ""
auth_values = headers["authorization"][0]["value"].split()
if not (
len(auth_values) == 2 and auth_values[0].lower() == "bearer" and auth_values[1]
):
return False
token_string = auth_values[1]
return token_string
In the example you can see we expect the header to include an authorization part where we also need a bearer followed by the token, split by a blank.
Verify the token
If you want to know more about the JWT token you obtained by cognito, go to jwt.io and test their debugger. Don’t worry the token will never leave jwt.io’s client side. So decoding is done completely in the frontend. I’m not as much into tooling on that topic, but jwt.io is the only place I would paste a token. Anyways when you use their debugger, you’ll see that there are different parts this token consist of.
- Token header
- Token payload (data)
- Tokens verify signature
All the token parts are split by . in the token string and contain different information.
The header contains kid (key id) and the encryption algorithm e.g. RS256.
To verify if a token comes from our identity provider we take information the IDP gives us
and decode the token. So you need the following parameters of your user pool:
- Region
- User pool id
- Client id
Imho the actual decoding should be left to the pros who know what they do - and everybody
is lazy anyways. So python-jose is the way to go for decoding JWT tokens. For more detail
see the python-jose github-repo.
I came across python-jose trying to implement verification with pycognito. A nice
project handling the cognito oauth flow for you. Downside was that it’s already too large
for the usecase in lambda@edge, since the bundled package doe not pass lambda@edge’s 10 MB
restriction. So I went forward taking just the parts required for decoding the access_token.
If you want to see where the TokenVerifier code came from have a look at
pycognito.
class TokenVerificationException(Exception):
"""Raised when token verification fails, taken from https://github.com/pvizeli/pycognito."""
class TokenVerifier:
"""Simpler version of https://github.com/pvizeli/pycognito."""
def __init__(
self, user_pool_id: str, client_id: str, pool_region: str, pool_jwk=None
):
self.user_pool_id = user_pool_id
self.client_id = client_id
self.pool_region = pool_region
self.pool_jwk = pool_jwk
@property
def user_pool_url(self):
"""Construct the user pools jwks url (details at: https://github.com/pvizeli/pycognito)"""
return f"https://cognito-idp.{self.pool_region}.amazonaws.com/{self.user_pool_id}"
@property
def user_pool_jwks_url(self) -> str:
"""Construct the user pools jwks url (details at: https://github.com/pvizeli/pycognito)"""
return f"{self.user_pool_url}/.well-known/jwks.json"
def get_keys(self) -> Dict:
"""Get public keys from cognitos jwks (details at: https://github.com/pvizeli/pycognito)"""
if self.pool_jwk:
return self.pool_jwk
# If it is not there use the requests library to get it
else:
self.pool_jwk = requests.get(self.user_pool_jwks_url).json()
return self.pool_jwk
def get_key(self, kid) -> str:
"""Get key from pools jwk json 'kids' (details at: https://github.com/pvizeli/pycognito)"""
keys = self.get_keys().get("keys")
key = list(filter(lambda x: x.get("kid") == kid, keys))
return key[0]
def verify_token(
self, token: str, id_name: str = "access_token", token_use: str = "access"
) -> Dict:
"""Verify token using jwt (details at: https://github.com/pvizeli/pycognito)"""
kid = jwt.get_unverified_header(token).get("kid")
hmac_key = self.get_key(kid)
try:
verified = jwt.decode(
token,
hmac_key,
algorithms=["RS256"],
audience=self.client_id,
issuer=self.user_pool_url,
options={
"require_aud": token_use != "access",
"require_iss": True,
"require_exp": True,
},
)
except JWTError:
raise TokenVerificationException(
f"Your {id_name!r} token could not be verified."
) from None
token_use_verified = verified.get("token_use") == token_use
if not token_use_verified:
raise TokenVerificationException(
f"Your {id_name!r} token use ({token_use!r}) could not be verified."
)
return verified
The decoded token returned by verify_token(...) will be a dictionary, which will hold
key-value pairs (decoded token content). At this point we already have everything we want.
A header check, token verification and decoding. Everythin we now need to do is further check
the tokens content. This could look like this:
# List of user_info in access_token to check
required_user_info = (
"sub",
"cognito:groups", # only required when working with groups
"token_use",
"scope",
"auth_time",
"iss",
"exp",
"client_id",
"username",
)
def check_token_access(access_token: Dict) -> bool:
"""Check token contents (user_info and expectation)"""
# Check if all required user_info is present in token
if not all(
[
(user_info in access_token.keys() and access_token[user_info] is not None)
for user_info in required_user_info
]
):
return False
# Check if the token content matches expectation
if not (
access_token["token_use"] == "access"
and access_token["iss"]
== f"https://cognito-idp.{REGION}.amazonaws.com/{USERPOOLID}"
and access_token["client_id"] == CLIENTID
):
return False
return True
Further checks
The only thing missing from here on is specific checks, based on the request compaired to the passed token. Here one can do different things here some examples:
- Match
sub(subject) and match it to requesteduri - Match
cognito:groupand match it to requesteduri - Match
cognito:<custom-attribute>and match it to requesteduri
Some ideas:
def check_authorized_group(
cloud_front_request: Dict, token: Dict, path_modifier: Callable = hashlib.md5
) -> bool:
"""Checks if 'cognito:group' is path of requested route"""
token_group = token["cognito:group"]
if path_modifier:
token_group = path_modifier(token_group)
return token_group in cloud_front_request["request"]["uri"]
Wrap it up
Lastly we remove the Authentication header, so Cloudfront can handle the request itself, by passing the input request back to Cloudfront.
def modify_request(cloud_front_request: Dict) -> Dict:
"""Remove header from viewer request for cloudfronts origin request"""
del cloud_front_request["headers"]["authorization"]
return cloud_front_request
Here is what the lambda_handler(...) looks like:
REDIRECT_302 = {
"status": "302",
"statusDescription": "Found",
"headers": {"location": HEADERS["location:redirect_uri"]},
}
# On failure return the following response
DEFAULT_RESPONE = REDIRECT_302
def lambda_handler(event, context):
"""Lambda handler"""
cf_request = event["Records"][0]["cf"]["request"]
headers = cf_request["headers"]
header_check = check_headers(headers)
if isinstance(header_check, bool) and header_check is False:
print("An error occured (invalid header):")
return DEFAULT_RESPONE
token_string = header_check
token_verifier = TokenVerifier(USERPOOLID, CLIENTID, REGION)
decoded_token = {}
try:
decoded_token = token_verifier.verify_token(
token_string, "access_token", "access"
)
except (TokenVerificationException, JWTError, JWSError) as e:
print("An error occured (token verfication failed):")
print(e)
return DEFAULT_RESPONE
if not check_token_access(decoded_token):
print("An error occured (unauthorized token content):")
return DEFAULT_RESPONE
# Just an example of using the requested path
if not check_authorized_route(cf_request, decoded_token):
print("Unauthorized sub in access_token:")
return DEFAULT_RESPONE
response = modify_request(cf_request)
print(response)
return response
With the REDIRECT_302 response, cloudfront will redirect users to the uri in
locations header. This can be the uri pointing to the cognito hosted-ui or frontends
login page. From there on users can log in, and the authentication flow will start, until
a valid access token is obtained by the user.